Field Note 001: Deconstructing the CDP: Why I’m Building My Own Marketing Stack
I have a rule about engineering: You don't truly understand a tool until you've tried to build a bad version of it yourself.
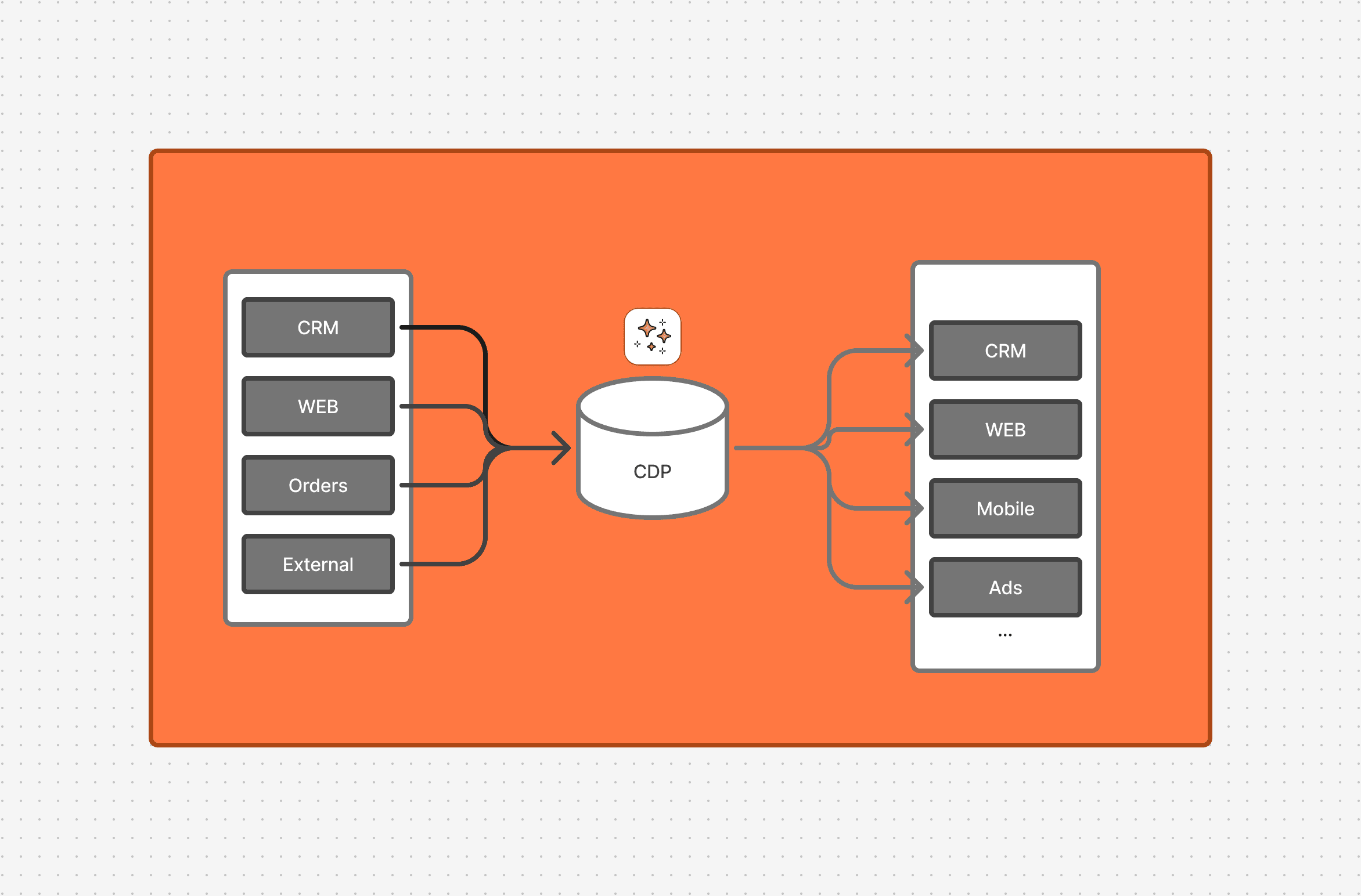
During the day, I work with massive Marketing Technology Stacks. These include CDPs, Marketing Automation tools, Data Warehouses, and more. These tools, which cost hundreds of thousands a year, are often seen as "Black Boxes." You feed data in, "magic" happens, and emails go out.
But as Architects, we can't trust magic. We need to understand the physics.
- What does "Real-Time" actually mean?
- How is identity resolved across multiple profiles?
- How do these boxes process so much information without crashing?
I wanted to stop guessing. So, this weekend, I decided to strip away the enterprise UI and build a scaled-down, Serverless Customer Data Platform (CDP) for my own site.
My goal wasn't to replace Enterprise products. My goal was to uncover what hides under the hood.
The Architecture: The "Event Bus"
Under the endless configuration screens and fancy UIs, a CDP is, at its core, a system that:
- Ingests data.
- Holds the data.
- Activates the data (syncing to a database or calling another system).
To reproduce this core architecture, I chose the following serverless stack:
- Ingestion: Cloudflare Workers (for accepting the events).
- Buffer: Cloudflare Queues (for putting the events on hold so we don't block the user).
- Brain: Supabase (Postgres) (for storing data and handling identity).
I chose Cloudflare because it runs on the Edge. If a user visits my site from London, the code runs in London. This guarantees speed.
For the database, I chose Supabase (Postgres). While the database itself isn't distributed on the edge (it lives in a specific region, like us-east-1), it offers the strong consistency we need for user profiles—something edge databases often struggle with. Plus it’s easy to use.
1. The Ingestion Engine (Validation at the Edge)
Most marketers think "Ingestion" is just pasting a webhook URL into a tool. But if you accept raw data without checking it, your database becomes a swamp.
I built my Ingestion Layer on Cloudflare Workers. It spins up in less than 10ms, handles traffic spikes, and most importantly, Validates the data before letting it in.
I use Zod to define the strict "Contract" for an event. If the payload doesn't match, the Worker rejects it immediately
Validation is critical here. Since my database is centralized (and "far away" from some users), we don't want to waste resources sending bad data across the ocean.
The Worker logic is simple: Validate, Queue, and Respond.
We do not write to the database here. That is too slow. We push to a Queue and return 200 OK instantly.
The Lesson: "Real-time" doesn't mean synchronous. It means Asynchronous but Fast. The Queue protects my database from crashing if a blog post goes viral (not that that would happen 😊).
2. The Processor (Asynchronous Consumption)
Now that the event is safely in the Queue, we need something to pick it up and actually put it into the database.
This is where the magic of decoupling happens.
If Supabase is having a bad day and takes 500ms to respond, my website visitors do not feel it. The Ingestion Worker (Step 1) has already returned 200 OK. The Queue Consumer runs in the background, invisible to the user.
In Cloudflare Workers, we export a queue handler alongside our fetch handler. It receives a batch of messages (not just one), which is great for performance.
The Lesson: Separation of concerns. The Ingestion Layer optimizes for Availability (accepting requests fast). The Processing Layer optimizes for Consistency (ensuring data is accurate). By putting a Queue in the middle, we get both.
3. The Identity Graph (Stitching in SQL)
This is the "Black Box" part of every CDP.
How do you know that cookie_123 is actually hello@lucascosta.tech? Vendors sell this as "AI Powered Identity Resolution." In reality, it’s usually just a SQL logic tree.
I implemented Deterministic Identity Resolution using a Postgres RPC function. It isn't magic; it is a graph problem.
- Scenario A: See a Cookie I don't know? Create Profile.
- Scenario B: See an Email I know? Link Cookie to Profile.
- Scenario C: See a Cookie and an Email that belong to different profiles? MERGE.
Here is the "Brain" of the operation:
Why use SQL instead of JavaScript?
You might ask: Why not handle this logic in the Worker?
If I did this in JavaScript, I would have to make 4 different trips to the database (Find Email, Find Cookie, Update, Delete). By moving this logic to a Postgres Function (RPC), it happens in one single atomic transaction. It is faster, and it ensures my data never gets corrupted if a request fails halfway through.
The Lesson: Identity is a Database Problem, not a pixel problem.
What will I use this for?
Mostly to understand behavior on my website. This exact stack is actually running on this blog right now! Every time you load a page or subscribe to my newsletter, those events are fired, queued, and processed into my database a few milliseconds later.
Note: Privacy is paramount here. Identifiable events should ONLY be collected if the user has granted explicit consent.
The Economics: $50k vs. $5
This entire stack costs me roughly $5/month to run. An Enterprise CDP starts at $50,000/year.
Am I saying you should fire your vendor and build this?
DEFINITELY No.
When you buy an Enterprise CDP, you are paying for the SLA, the Compliance Team, and the UI that lets non-technical marketers build audiences. My "Toy CDP" is 100% code.
But for the Marketing Engineer—the person who needs to build custom logic, handle weird edge cases, or spin up a micro-service for a specific campaign—understanding this architecture is a must.
You stop seeing "Tools" and start seeing "Primitives." And once you see the primitives, you can build anything.
Stay tuned for the next post in the series, where we will dive deeper into how CDPs work and how you can build a scaled-down version of it yourself.
(I am open-sourcing the code for this entire project at the end of the series. Make sure you subscribe to my newsletter to get the full project link and more resources.)
Enjoyed this post?
Subscribe to get insights on marketing engineering, data-driven growth, and building better systems.
No spam. Unsubscribe anytime.